Gostaria de saber qual a sequência correta para baixar o XML de uma nota pela chave de acesso nos endpoints de distribuição, queria saber também o consumo, eu vi que: tenho que usar o Manifestar para fazer ciência ou confirmação (consome 1 crédito), depois tenho que usar o Distribuir documentos pela chave apenas para pegar o id para baixar o XML, (consome 1 crédito) depois depois faço o download do XML e esse parece que não consome de novo, seria então 2 créditos para fazer um download de XML? não tem uma forma do evendo de manifesto já enviar o id para download evitando consumir 2 créditos?
Bom dia!
Acredito que nosso amigo @suporte345 possa corrigir ou complementar com mais informações.
Mas quando falamos no processo de Distribuição DFe, podemos definir os passos do processo como um ciclo:
- Executo a consulta de DistribuicaoDFe pelo ultNSU e recebo os XMLs completos e resumos.
- Faço o envio de um evento de manifestação conclusiva.
- Executo a Consulta de DistribuicaoDFe pelo ultNSU e recebo os XMLs completos das notas que manifestei no passo 2 e novos resumos.
Repito esse processo até ulsNSU ser igual a maxNSU.
Transcrevendo isso para os end-points da Nuvem acredito que ficaria assim:
- GerarDistribuicaoDFe que consome 1 unidade por documento distribuído (retornado) ou requisição.(Podem ser devolvidos até 50 documentos por consulta então pode consumir até 50 unidades já que é por documento distribuído)
- ManifestarNFe que consome 1 unidade por requisição.
- BaixarXmlDocumentoDistribuicaoDFe que não tem na referência da API informação sobre consumo.
- GerarDistribuicaoDFe que consome 1 unidade por documento distribuído (retornado) ou requisição.(Podem ser devolvidos até 50 documentos por consulta então pode consumir até 50 unidades já que é por documento distribuído)
Nesse processo, você faz o controle do seu lado, você vai ver no retorno do GerarDistribuicaoDFe quais documentos são resumos que precisam ser manifestados, quais documentos são completos e precisam ser armazenados.
Agora se você não fizer esse controle e deixar isso a cargo da API, entram novos endpoints como o ListarDocumentos, ConsultarDocumento ou ListarNFeSemManifestacao
1 curtida
Excelente explicação, @diego.foliene.
Só complementando com alguns pontos que podem enriquecer ainda mais o entendimento do processo:
Os endpoints que você citou são exatamente os mesmos utilizados tanto na distribuição manual quanto na distribuição automática. A diferença está apenas na orquestração: na distribuição automática, a própria API da Nuvem Fiscal gerencia o ciclo completo de distribuição e manifestação com o objetivo de obter o XML completo das notas emitidas contra um CNPJ ou CPF. Já no processo manual (como o descrito por você), o controle fica totalmente por conta do integrador. Mas os endpoints envolvidos são os mesmos em ambos os casos.
Além disso, é interessante destacar que a API também oferece suporte à ciência automática, que é uma funcionalidade independente da distribuição automática. Ou seja, é possível ativar apenas a ciência automática, apenas a distribuição automática, ou utilizar ambas em conjunto, dependendo da necessidade do projeto. Com isso, ao receber um resumo de NF-e (mesmo que de forma manual), a própria API pode registrar automaticamente a ciência da operação em nome do destinatário, agilizando ainda mais o fluxo de recuperação do XML completo.
Vale lembrar, no entanto, que essa manifestação de ciência da operação, apesar de suficiente para que o XML completo seja disponibilizado pela SEFAZ, não substitui a obrigatoriedade da manifestação conclusiva, que deve ser feita dentro do prazo legal previsto na legislação. A API não realiza esse tipo de manifestação de forma automática, cabendo ao próprio usuário da API realizar o envio quando necessário.
1 curtida
distribuição automática se eu ativar como funcionará, qual o procedimento eu devo adotar para ter os xml, no caso a nuvem gera automatico a distribuição todos os dias, como seria isto?
seria possivel mostrar um roteiro para cada situação?
Boa tarde, @gfflogsystem.
A distribuição automática, por padrão, será realizada a cada 24 horas pela API. Para alterar, basta requisitar o endpoint Alterar configuração de Distribuição de NF-e:
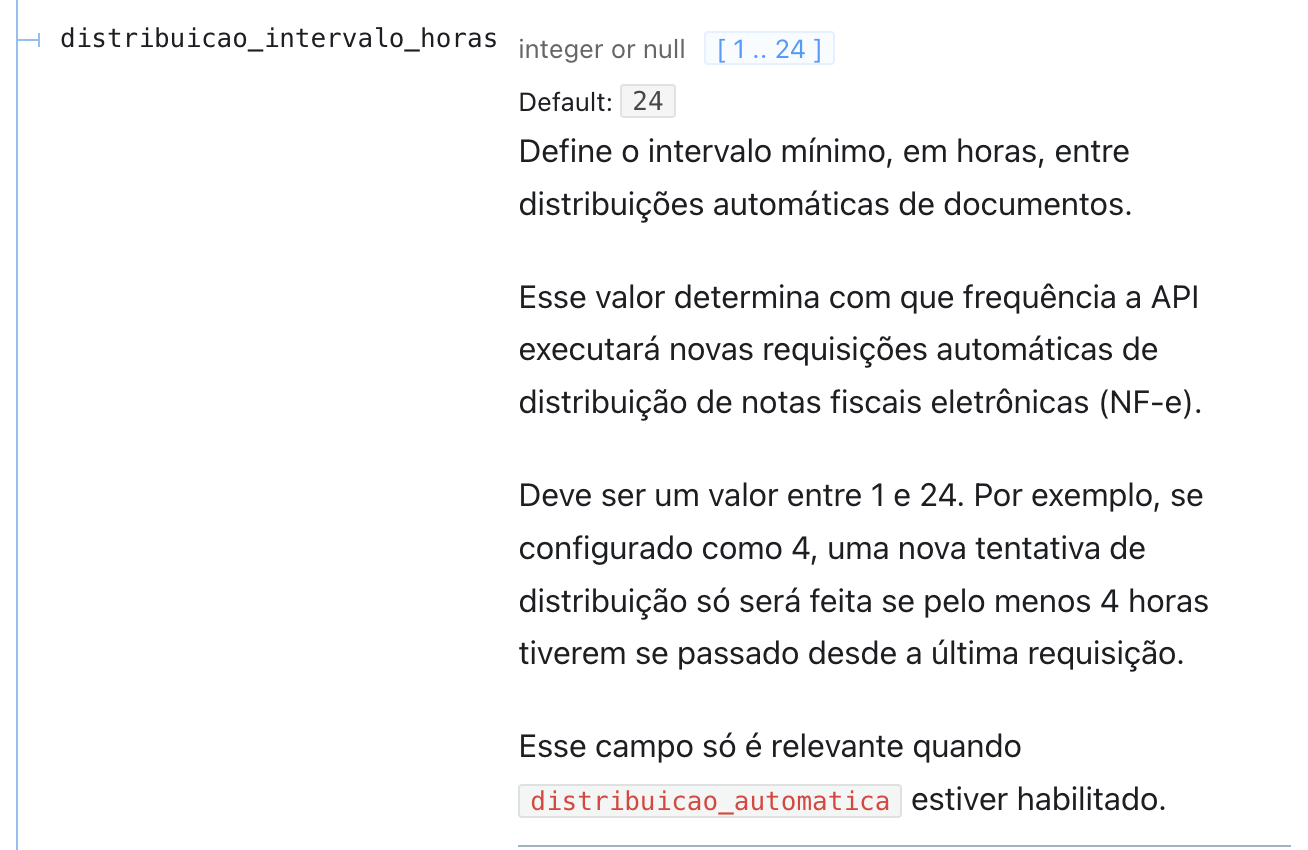
Caso tenha mais alguma dúvida específica, estamos à disposição.
1 curtida